
LEBERT
paper : Lexicon Enhanced Chinese Sequence Labeling Using BERT Adapter
source: ACL 2021
code: LEBERT
PS:此项工作的作者,与WC-LSTM是相同的作者。。
本文最核心的贡献是:作者提出了在BERT的底层注入词汇特征的方法,充分地利用上BERT模型的序列建模能力。
1: BERT-level Fusion
许多工作尝试将BERT与词汇特征进行结合,来进行中文的NER任务。当前较为普遍做法如下图(a)所示,首先使用BERT对字符序列进行建模,捕获字符之间的依赖关系,然后将BERT输出的字符特征与词汇特征进行融合,最后输入到神经网络标注模型中。
该方法在一定程度上能够将词汇特征引入序列标注模型中,但由于仅在BERT末端的浅层神经网络中引入词汇特征,没有充分地利用上BERT模型的序列建模能力。因此,作者提出了在BERT的底层注入词汇特征的方法,模型整体示意图如下图(b)所示。

2: Char-Words Pair
在WC-LSTM的工作中,挂词方式是存在信息缺失的问题,所以,在本工作中,作者对信息缺失这个问题进行了改进,类似地参照了SoftLexcion的工作,但并没有更细节化的区分BMES的分类。
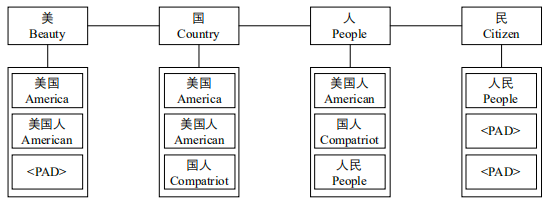
为了在模型中引入词语特征,作者设计了一种字符-词语对(Char-Words Pair)的结构,对于输入文本中的每个字符,找出它在输入文本中匹配到的所有词语。
对于下图中的输入文本【美国人民】,字符【美】匹配到的词语为【美国、美国人】,字符【国】匹配到的词语为【美国、美国人、国人】,以此类推。其中,作者会提前构建一棵字典树(Trie树),用来匹配输入序列中的词语,然后得到每个字符对应的词语序列。
给定长度为n的输入序列Sc={c1,c2,...,cn},
其中,ci表示输入序列中的第i个字符。
使用字典树进行词语匹配,得到每个字符对应的词语列表ws={ws1,ws2,...,wsn} ,
其中,wsi表示第i个字符匹配到的词语列表。
最终,得到字符-词语对scw={(c1,ws1),(c2,ws2),...,(cn,wsn)}作为模型的输入。
3: Lexicon Adapter
作者在原始的Transformer中,设计一个将字-词特征进行融合的模块结构,对原Transformer进行魔改。
对Lexicon Adapter结构的输入:(hic,xiw)
其中:
hic,表示第i个字符,在某一个Transformer layer输出的特征向量表示;
xiw={xi1w,xi2w,...,ximw}是一个词向量列表,xijw表示第i个字符匹配到的第j个词向量。
整个Lexicon Adapeter的结构可以分成如下这3个部分:

维度映射
将Transformer输出的特征向量hic与词向量xijw进行非线性映射,将维度进行映射统一
vijw=W2(tanh(W1xijw+b1))+b2词表attention加权
令Viw={vi1w,vi2w,...,vimw}表示第i个字符的挂在词表,每个词的attention weight表示如下:
ai=softmax(hicWattnViT)然后将attention weight对词向量进行加权:
ziw=j=1∑maijvijw字-词向量线性融合
将原始输入的字向量,与加权后的词向量进行线性相加,得到融合向量输出hi:
hi=hic+ziw
将融合向量输出进行dropout、layer norm和残差连接等操作,得到Lexicon Adapter的最终输出。
4: Lexicon Adapter插入到原BERT位置

如图,将Lexicon Adapter与BERT相结合,得到最终的模型结构。
PS:其中Lexicon Adapter可以插到任意一个Tranformer Layer的后面进行词语特征融合。
作者关于插入的位置分别做了消融实验,发现Lexicon Adapter插到第一个Tranformer Layer后面的效果最好。

当Lexicon Adapter插到BERT的第一层后面时,模型效果最好,这大概率是由于字符信息与词语信息能够在BERT中进行更加充分的信息交互。
最后更新于