
NRE
1. 基于RNN的模型
下面2个模型都是算全监督学习下的模型范畴,并不涉及到MIL(多示例学习/远程监督)。
模型1.1:bi-LSTM on RE
论文连接:Zhang (2015). Relation classification via recurrent neural network.
1.1.1 模型创新点
其实,但从模型上来看,这压根就是一个标准的bi-LSTM模型的,这里面比较亮的创新点在于:
对于实体对显示的添加了Position indicators(位置指示符);
<e1>people<\e1>have been moving back into<e2>downtown<\e2>。就是直接在原句子中增加了2个字符的起始与停止的位置,然后就没有然后了。
对于bi-LSTM的处理:是直接将前向的output和后向output进行加和处理的:
ht=htfw+htfwPS:其实如果想做对比组试验的话,也可以使用拼接处理的。
在bi-LSTM后面添加的Max-Pooling操作的;
在原文中的解释是说:“RNN的反复连接的积累往往会很快忘记长期的信息,并且由于梯度消失的烦人问题,句子结尾的监督很难传播到模型训练的早期步骤。”
并且也阐述了选择Max-Pooling而非Mean-Pooling的原因:“作者认为句子中的关键词对于关系分类更重要,因此选择Max-Pooling”。
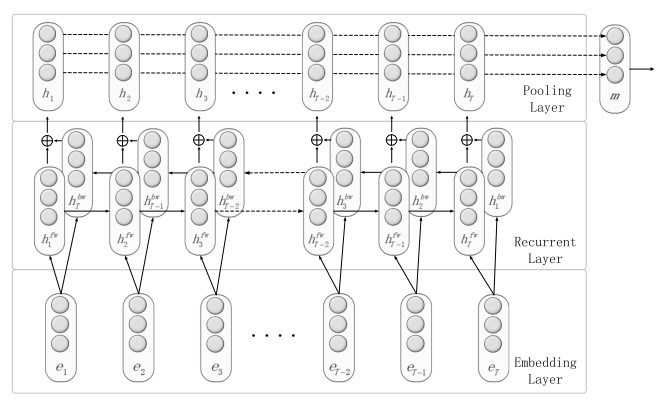
1.1.2 模型效果
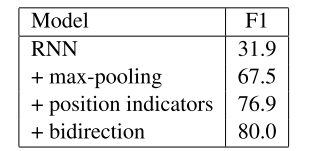
从自身来看的话,加了Position indicators(位置指示符)还是起到了很好的效果的。
而且对于RNN来讲,单单增加了max-pooling后,效果提升就非常明显了,还是有说法的!
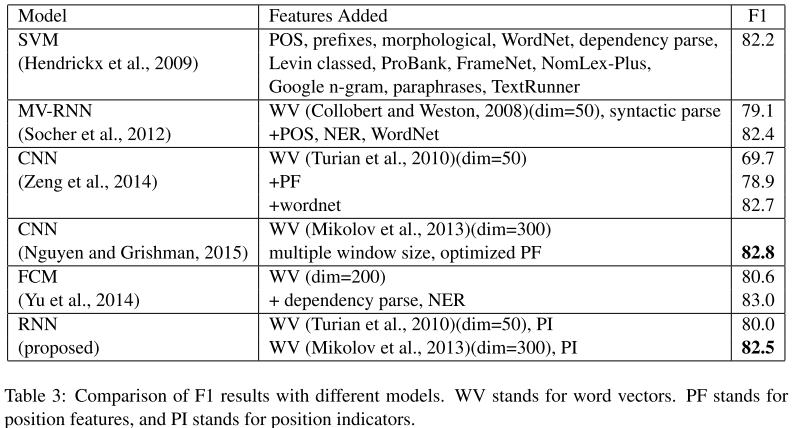
与其他模型比较来看的话,和使用多尺寸卷积核的CNN效果是持平的。(那个模型在CNN for RE中会详细分析到的)
模型1.2:Att-bi-LSTM on RE
1.2.1 模型创新点
模型称得上创新点也称不上创新点的:也就是在bi-LSTM上加attention了,这个应该算是attention is all you need之后的模型常规操作了,所以感觉模型创新点就很弱了,其他操作就和问题1中的模型完全一样的(当前去除了max-pooling)。
加的Attention应该算是self-attention吧(还是简化版的)?——后面补充上Attention的原理知识后,回到这里进行确认【TODO 待确认】!!
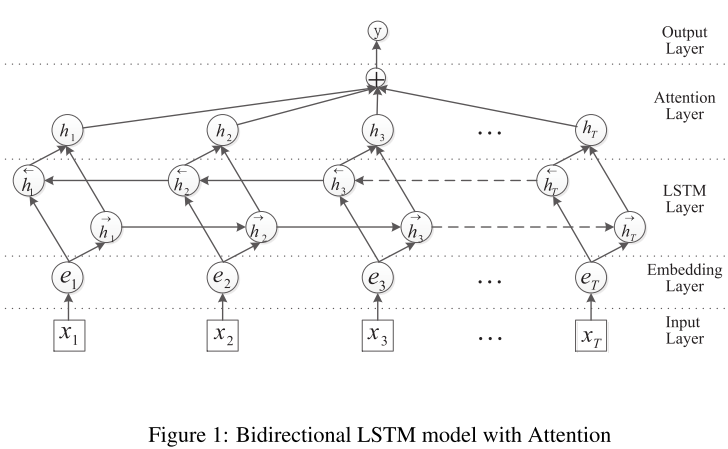
Attention Layer:其实就是一个对LSTM的每一个step的输出做一个加权的过程,而非仅仅只取最后一个step。设H为bi-LSTM所有step的输出矩阵,然后做如下操作后,得到最终attention计算后的weight vector:
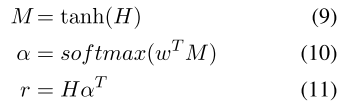
1.2.2 模型效果
感觉就是基本操作,没啥可太多评价,让人眼前一亮的地方,因为模型其实并没有针对于关系抽取做出太多眼前一亮的设计思路,所以,结果比较,,看看就好!
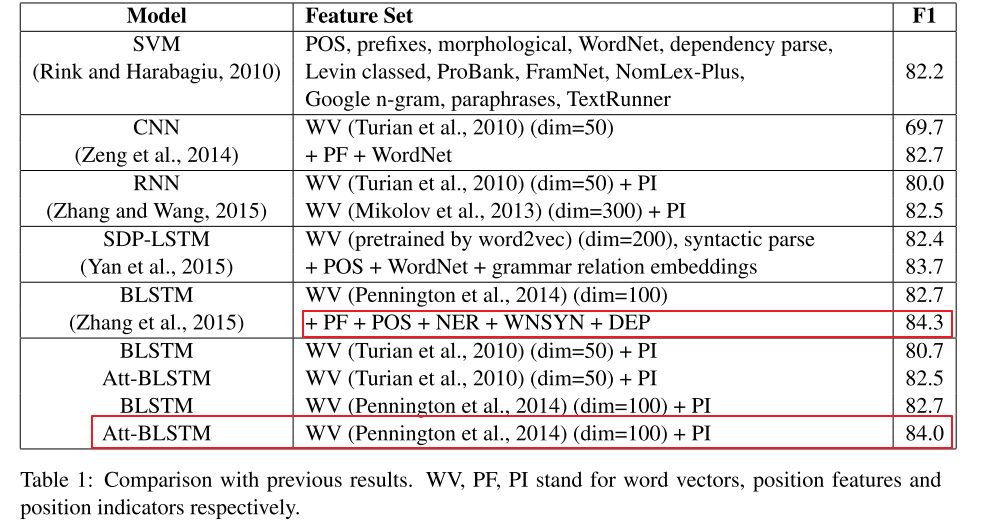
2. 基于CNN的模型
参考资料:https://shomy.top/2018/02/28/relation-extraction/
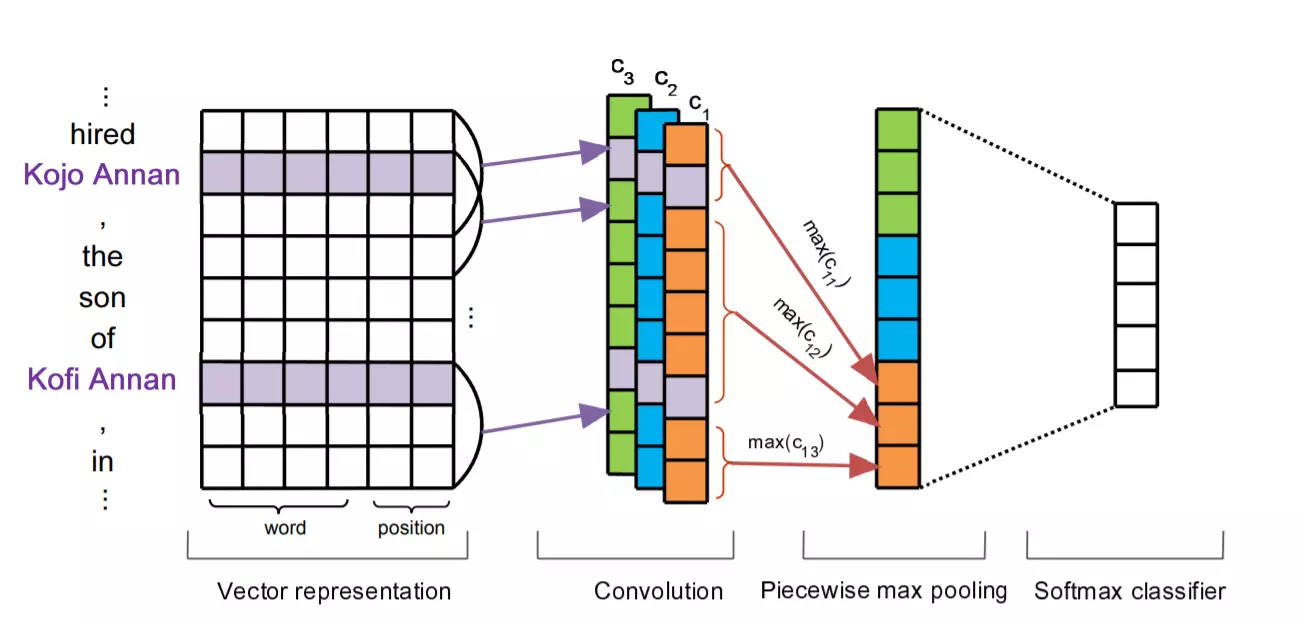
模型2.1: PCNN模型
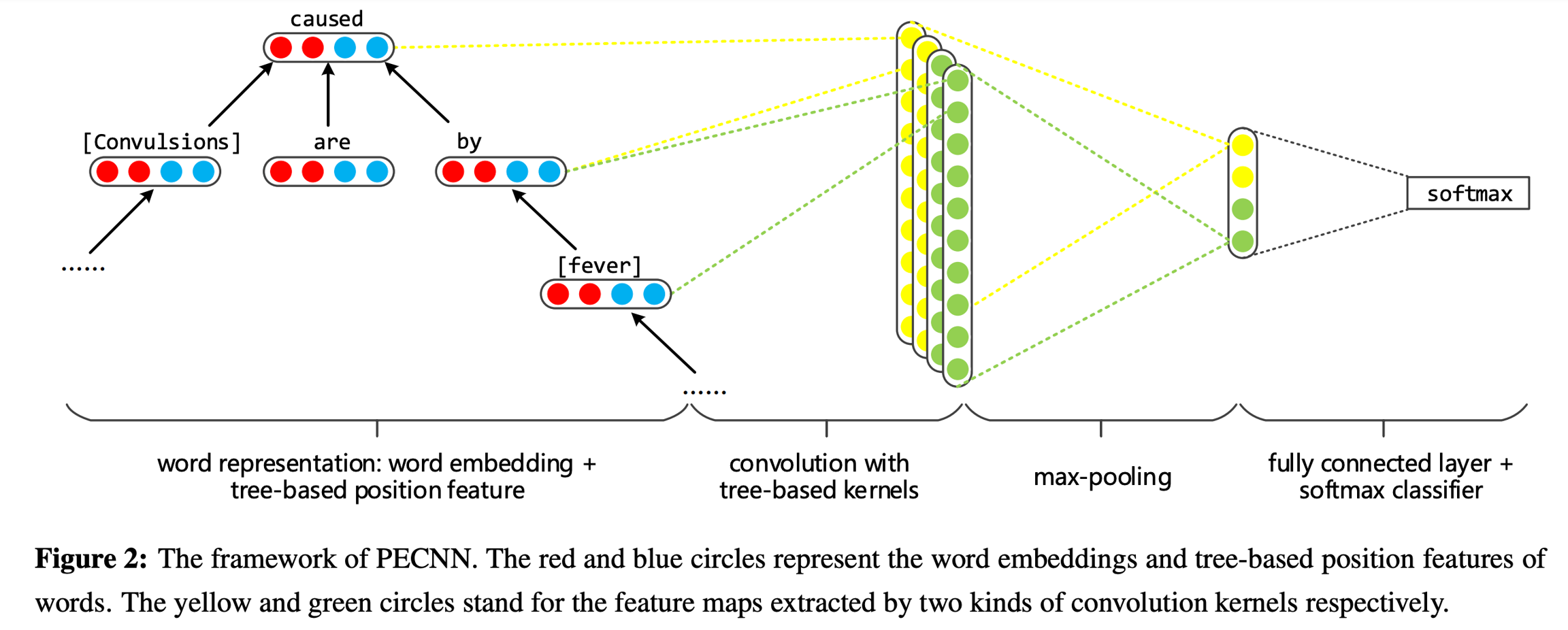
模型2.2: PECNN模型
参考资料:https://cloud.tencent.com/developer/news/197006
最后更新于