本章节用于整理机器学习中,一些比较零碎细小的知识板块。
当模型表现不佳的时候,通常会落入到两种问题中:高偏差、高方差问题。
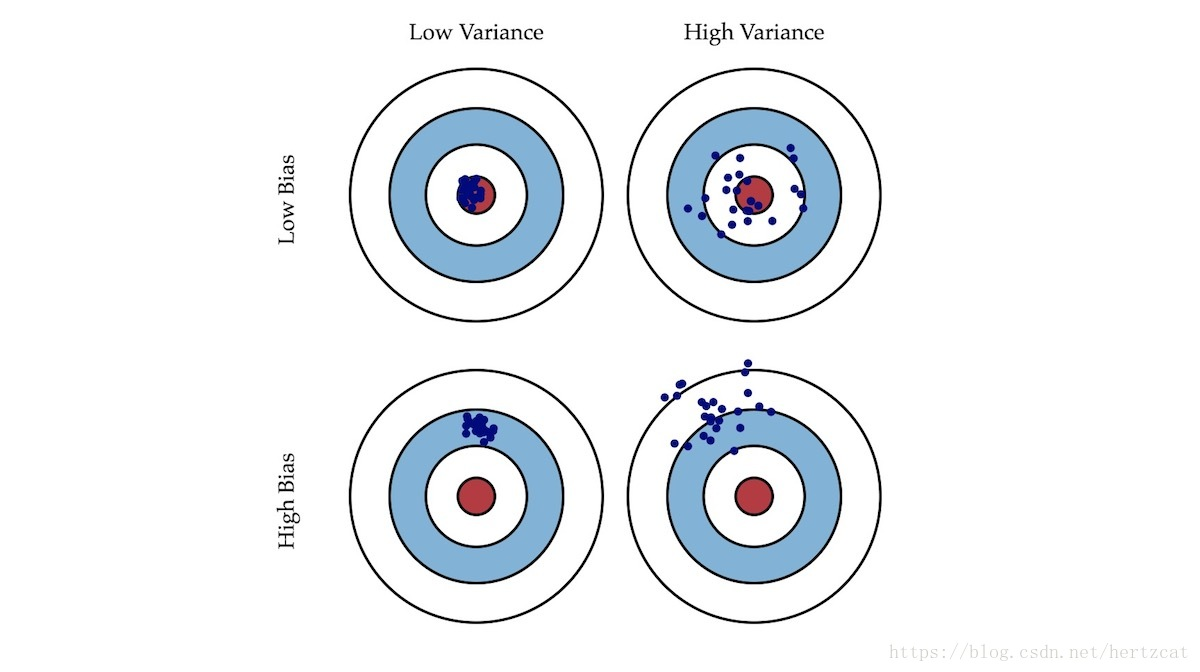
偏差:描述模型输出结果的期望与真值的差距,刻画的是模型对数据的拟合程度
方差:描述模型对于给定值得输出的稳定性,刻画的是数据扰动对模型的影响
就像打靶一样,偏差描述了我们的射击总体是否偏离了我们的目标,而方差描述了射击准不准。如下图:
高偏差问题可以理解为:模型的拟合能力太弱,未充分学习到数据的分布规律
高方差问题可以理解为:模型的过度学习了训练数据的分布规律,而在使用时受到微小扰动就会发生较大的波动,也就是过拟合
改进策略
使用场景
采集更多的数据
高方差
降低特征的维度/模型复杂度
设计更多的特征/提高模型复杂度
高偏差
也就是最大似然概率,假设一个观测事件是独立分布的,那么这个最有可能发生的序列的概率就是所有观测序列的乘积的最大值。
用简单的多项式函数近似的替代复杂函数,在已知函数在某一点的各阶导数值的情况之下,泰勒公式可以用这些导数值做系数构建一个多项式来近似函数。
最后更新于 6年前